Apache Lucene
Apache Lucene è una libreria di ricerca open source che offre funzionalità di indicizzazione e ricerca di testi. Ha ottime prestazioni, è scalabile e cross-platform dato lo sviluppo in Java, anche se vi sono porting in altri linguaggi.
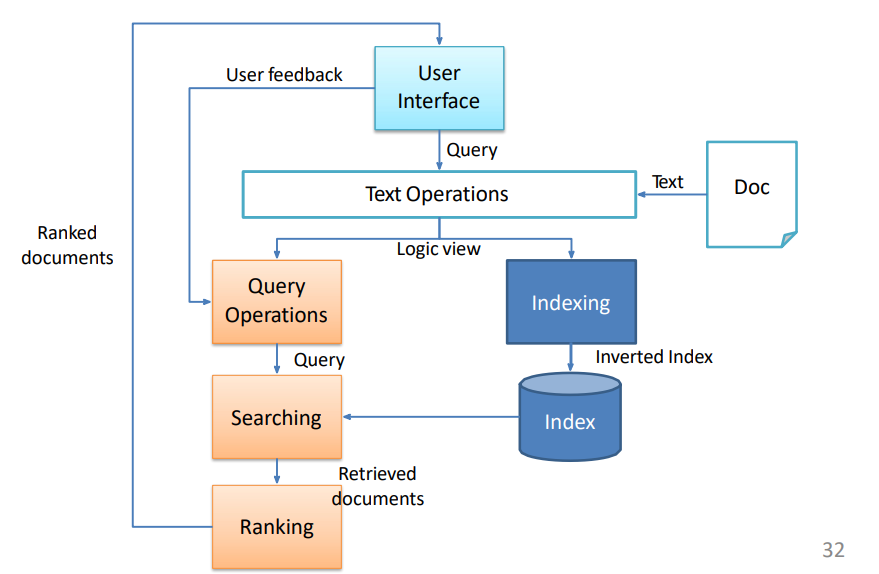
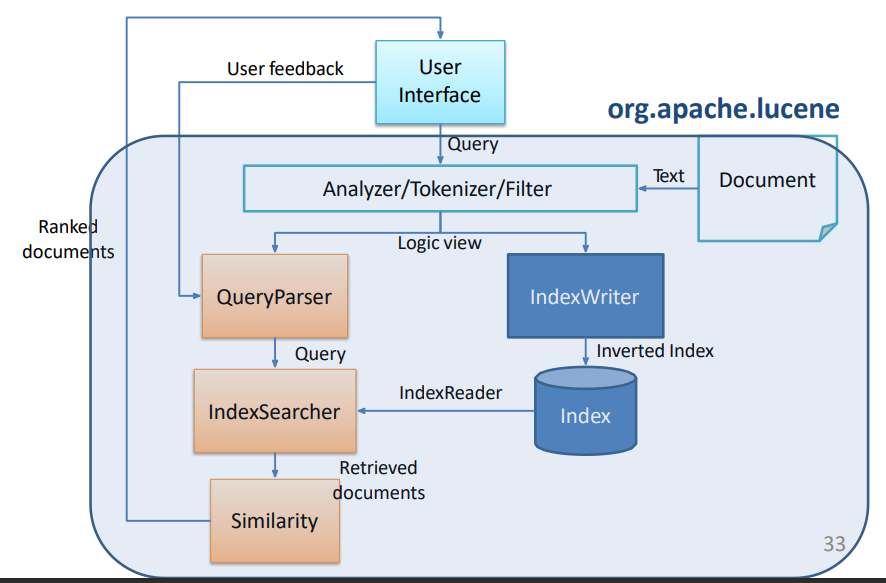
Lucene utilizza un modello ibrido tra il Vector Space Model e il modello Booleano, ovvero usa il Booleano per un pre-filtering dei testi, e su questi va ad effettuare i calcoli tipici del Vector Space Model.
Un documento è una collezione di campi che definiscono la struttura del documento. Ogni campo ha tre parti: nome, tipo e valore (testuale, binario, numerico). Un campo può essere memorizzato nell’indice nella versione originale (prima del processing) oppure no.
Pipeline di istruzioni per una ricerca
// Open a directory from the file system (index directory)
FSDirectory fsdir = FSDirectory.open(new File("./resources/helloworld").toPath());
// IndexWriter configuration
IndexWriterConfig iwc = new IndexWriterConfig(new StandardAnalyzer());
// Index directory is created if not exists or overwritten
iwc.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
// Create IndexWriter
IndexWriter writer = new IndexWriter(fsdir, iwc);
// Create document and add fields
// Field.Store.NO -> non salvo il contenuto del campo così com'è
Document doc = new Document();
doc.add(new TextField("super_name", "Spider-Man", Field.Store.NO));
doc.add(new TextField("name", "Peter Parker", Field.Store.NO));
doc.add(new TextField("category", "superhero", Field.Store.NO));
doc.add(new TextField("powers", "agility, spider-sense", Field.Store.NO));
// add document to index
writer.addDocument(doc);
// close IndexWriter
writer.close()
// Create the IndexSearcher
IndexSearcher searcher = new IndexSearcher(DirectoryReader.open(fsdir));
// Create the query parser with the default field and analyzer
// "name" è il campo di default, se non specificato nelle query cerca in questo campo
// Lucene non controlla se l'analyzer tra documenti e queryparser è lo stesso
QueryParser qp = new QueryParser("name", new StandardAnalyzer());
// Parse the query
Query q = qp.parse("name:parker powers:agility");
// Search
TopDocs topdocs = searcher.search(q, 10);
System.out.println("Found " + topdocs.totalHits.value + " document(s).");Operazioni sul testo
- Analyzer: crea il TokenStream che verrà usato per indicizzare e per la ricerca
- L’Analyzer più completo e potente è lo StandardAnalyzer
- Un altro esempio di Analyzer può essere l’ItalianAnalyzer, specifico per la nostra lingua
- Tokenizer: è un TokenStream responsabile di dividere il testo in token
- Primo step nel processo di analisi, il Tokenizer più completo è lo StandardTokenizer
- TokenFilter: TokenStream responsabile di modificare i token creati dal Tokenizer
- Esempi di TokenFilter sono LowerCaseFilter, che trasforma i token in minuscolo, oppure il PorterStemFilter che applica lo stemming
Fase di ricerca
- IndexReader: interfaccia per accedere all’indice
- QueryParser: parsa la query dell’utente
- IndexSearcher: implementa la ricerca su un IndexReader, costruendo un oggetto TopDocs che sarà il risultato della ricerca, ovvero i documenti rilevanti con il loro rank
Sintassi delle query
- Una query è formata da termini e operatori.
- Due tipi di termini, singoli (“test”) o frasi (“ciccio il cane di Lanubile”)
- L’analizzatore usato per creare l’indice verrà utilizzato anche sui termini e sulle frasi della query
- Ricerca in specifici campi:
title:"The Right Way"cerca la frase “The Right Way” nel campo title.- Ricerche Wildcard: per cercare un singolo carattere si usa ? (
te?tmi trova text o test ad esempio), per più caratteri il classico *- Non possono essere usati come primo carattere
- Regex
- Fuzzy Search: utilizza la distanza di Levenshtein e si realizza con la tilde ~ al termine del singolo termine (
roam~, la ricerca troverà termini simili a roam)- Un parametro addizionale specifica quanti edit sono ammessi (
roam~1), ma questa sintassi verrà deprecata
- Un parametro addizionale specifica quanti edit sono ammessi (
- Ricerca in prossimità: fuzzy search applicata alle frasi (
"jakarta apache"~10cercherà apache e jakarta a una distanza massima di 10 parole l’uno dall’altro) - Range queries: permette di specificare limite inferiore e limite superiore di una ricerca. Ad esempio
data:[20020101 TO 20030101]prenderà i documenti il cui campo data è compreso tra quei due valori, inclusi.- Con le parentesi graffe invece vengono esclusi i due termini. E’ possibile realizzarle anche con delle parole e non solo con delle date o dei numeri.
- Boostare un termine: con la sintassi
qls^numaccanto a un termine o una frase si boosta la rilevanza di quel singolo termine.ciccio^69
- Operatori booleani (OR, AND, NOT)
- +: il termine a cui si riferisce deve esistere in quel campo
+"frase a caso"
- -: il termine non deve esistere in quel campo
-"terrorismo"
- +: il termine a cui si riferisce deve esistere in quel campo
- E’ possibile raggruppare le clausole con le parentesi tonde, a denotare quindi il loro scope
- Ricerche Wildcard: per cercare un singolo carattere si usa ? (
Posting API
Vediamo ora come avere accesso al term frequency, alla posizione e all’offset dei termini.

L’API ci mette a disposizione i seguenti oggetti:
- Field è l’entry point dell’API
- Terms è la collezione dei termini del Field
- TermsEnum è l’iteratore di Terms
- PostingEnum è l’iteratore dei documenti, delle posizioni di un termine e dell’offset.
Memorizzare la posting list
//define a custom field type that stores post information
FieldType ft = new FieldType(TextField.TYPE_NOT_STORED); // non memorizzo contenuto originale, faccio solo tokenizzazione e indexing
ft.setStoreTermVectors(true); // salva all'interno dell'indice invertito
ft.setStoreTermVectorPositions(true); // salva vettore posizione parole
ft.setStoreTermVectorOffsets(true); // salva offset delle parole
// All'aggiunta di un campo passiamo ft come FieldType
Document doc1 = new Document();
doc1.add(new StringField("id", "1", Field.Store.YES));
doc1.add(new Field("text", new FileReader("./resources/text/es1.txt"), ft));Ottenere la BoW di un documento
Terms terms = field.terms(field);
TermsEnum termsEnum = terms.iterator();
PostingsEnum postings = termsEnum.postings(null, PostingsEnum.FREQS)
while (postings.nextDoc() != DocIdSetIterator.NO_MORE_DOCS) {
System.out.println(":" + postings.freq());
}Ottenere posizione e offset
PostingsEnum postings = termsEnum.postings(null, PostingsEnum.ALL); // iteratore della posting list
while (postings.nextDoc() != DocIdSetIterator.NO_MORE_DOCS) {
System.out.print(":" + postings.freq()); // TF
for (int i = 0; i < postings.freq(); i++) { // per ogni occorrenza
int position = postings.nextPosition(); // prendi la prossima posizione
// operazioni da svolgere
// stampa posizione, offset partenza e offset destinazione
}
}